Agent Harness:模型之外的那层工程
聊 Agent 的时候,大家很容易把"模型更强"等同于"Agent 更好用"。但只要你真跑过几次长任务就知道不是这么回事——同一个模型,换一套工具配置,表现可以从"靠谱同事"变成"原地打转的实习生"。模型没换,结果天差地别。
问题出在模型外面。它能不能形成有效的执行循环,拿到的信息对不对,反馈快不快,边界清不清楚,做完了有没有人真去验。这套东西,Anthropic 叫它 agent harness,LangChain 给了个更好记的公式:Agent = Model + Harness。
这不是文字游戏。它传递的工程判断是:当模型从聊天框走进工具调用循环、开始干活的时候,可靠性的大头不在模型本身,在模型周围的工程设计。
这个词怎么来的
Harness 中文社区翻译五花八门——"驾驶舱""执行骨架"或者干脆不翻。但指向的问题一样:模型只会推理,Agent 需要行动、犯错、修复、接着行动。让一个不完美的推理器做到这些,靠的是外部的执行结构和反馈链路。
Mitchell Hashimoto 2026 年 2 月那篇《My AI Adoption Journey》把自己用 AI 写代码的过程分了几个阶段,最后一步就是 "Engineer the Harness"——主动改造 Agent 的运行环境。这篇文章让 harness 作为独立工程对象的认知大范围传开了。
Anthropic 同年 1 月的 evals 文章给了更精确的定义:agent harness 是让模型以 agent 身份行动的系统,管输入、管工具调用编排、管结果返回。同一篇文章还区分了 evaluation harness——跑 Agent 的和测 Agent 的是两套东西,这条边界很容易被忽略。
几个容易混的概念
Workflow 和 Agent 不是一回事。 Workflow 是你画好的流程图,代码路径是确定的;Agent 是模型自己决定下一步干什么。Harness 存在的前提就是 agent 要在不确定性里工作。
Agent harness 和 evaluation harness 不是一回事。 前者让 agent 跑起来,后者是测试系统——跑完任务后看环境里实际产出了什么,打分。Anthropic 特别说过:评估一个 agent 其实是在同时评估 harness 和模型。任务跑通了不能直接说"模型好",因为 harness 可能替模型挡掉了一堆坑。
Prompt engineering、context engineering、harness engineering 是三个层次。 Prompt 管指令怎么写;context 管什么信息、什么时候、以什么精度进入上下文窗口;harness 的范围更大——在 context 之上还要管工具合约、状态持久化、沙箱、权限、回退策略和可观测性。"找到最小高信号 token 集合"是 harness 里最贴近模型的一环,但远不是全部。
Harness 里有什么
拆开看,是一组决定 agent 行为边界的工程表面:
Loop。 核心运转单元。接收 prompt → 模型评估回应 → 执行工具 → 结果返回 → 再次评估 → 直到终止。复杂任务会在几十个 turn 里推进,harness 负责把这个循环跑起来、跑下去。
Prompts / Instructions。 最终进入模型上下文的内容。但得说清楚:如果 harness 其他部分烂了,光靠 prompt 救不回来,长任务里尤其如此。
Tools。 Harness 里最外显的设计面。工具是确定性系统和非确定性 agent 之间的合约——描述、参数 schema、返回结构都直接影响 agent 的行为。从 agent 视角出发定义"我需要什么能力",比把一组 API 裹一层扔过去效果好得多。工具太多制造决策模糊,返回太大挤占上下文,出错时没有有用反馈则让 agent 无从修正。
Context & Memory。 模型没有跨窗口的持久记忆。Harness 管的是"什么时候放什么进上下文"。好的做法是保持轻量引用指针,需要细节时通过工具实时加载,别一股脑全塞进去。
Session / State。 长任务的状态必须活在上下文窗口之外。可以是 append-only 的事件日志,也可以简单到就是 feature list、progress log、git history 这些文件。Harness 保证下一段上下文能看到这些东西并接着干。
Sandbox / Runtime。 Agent 要执行代码、跑命令、操作文件、开浏览器。这些能力不属于模型,由 harness 提供。
权限、Hooks、预算、停止条件。 没有边界的 agent 不是工具,是风险。Harness 定义能做什么、不能做什么、什么时候该停。Hooks 可以拦截或阻止工具调用,成本上限防止它在死循环里烧钱。
Evals / Observability。 Agent 在环境里实际产出的东西,比它自己说的"搞定了"重要得多。Harness 需要同时采集 transcript(过程)和 outcome(产出),否则没法区分"说得好听"和"真做到了"。
Security Boundaries。 Agent 开始执行自己生成的代码时,安全就不是事后补丁了。把模型循环(大脑)和沙箱执行(双手)解耦,credentials 从 sandbox 中隔离出来,模型通过代理调用外部服务而不直接碰密钥——这是已经被验证过的设计。
长任务才是照妖镜
一两轮就结束的任务,harness 的问题不太露头。但任务一旦跨多个上下文窗口——模型对上一轮完全没有记忆——harness 的价值立刻暴露。
Anthropic 反复验证过的一个方案是 initializer agent 搭配 coding agent。Initializer 负责第一轮环境搭建:生成 init script、progress log、feature list,做好初始 commit。后面每次起一个新 coding agent,上下文里先注入这些结构化产物。Feature list 告诉它该干哪件事,progress log 告诉它已经做过什么、在哪卡过,init script 让它快速把项目跑起来,git history 记录代码变化的真实痕迹。
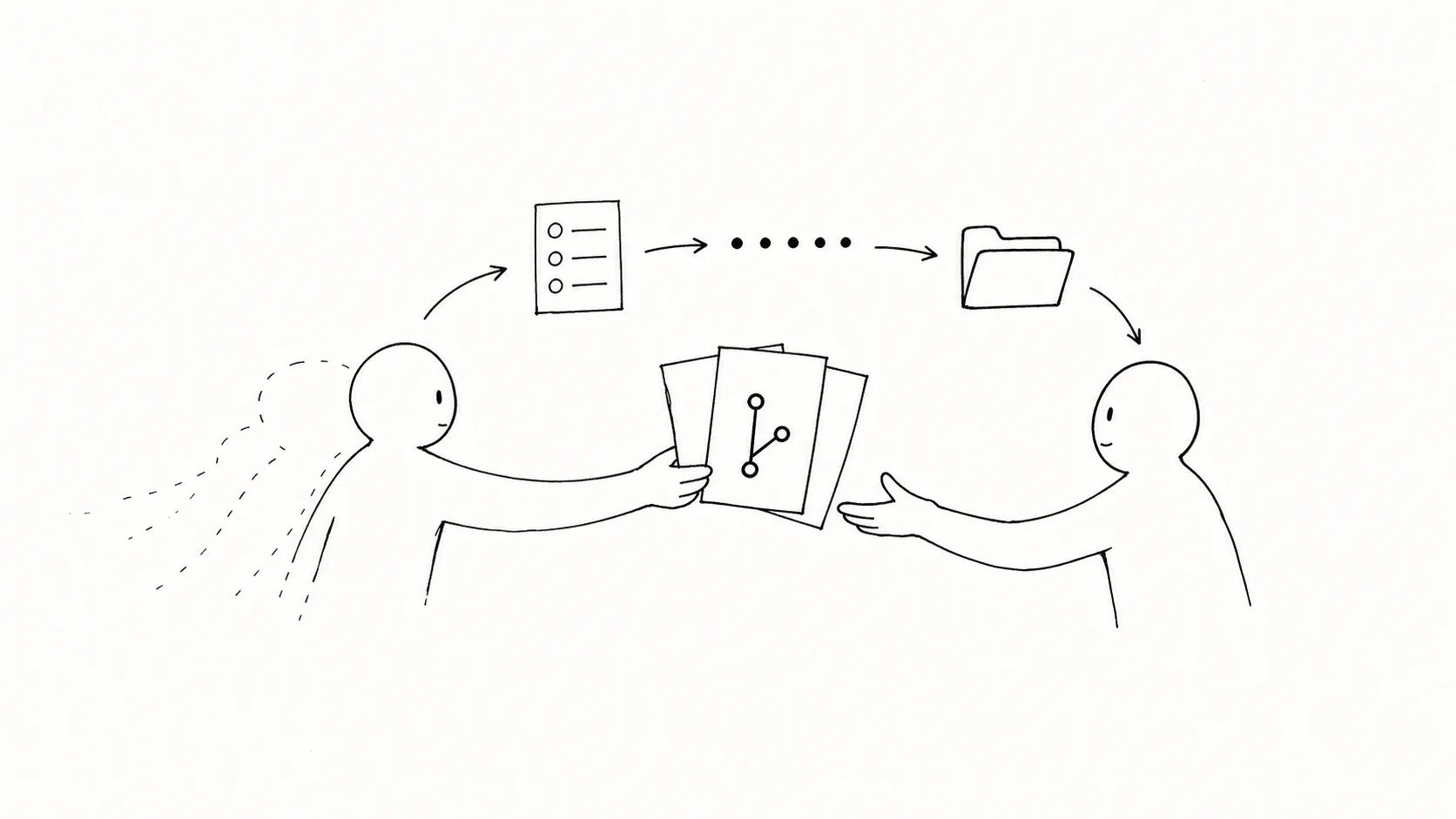
这些文件各自对治一种具体的失败模式:
- Agent 过早宣布完成 → feature list 把注意力锁在单一特性上。
- 写了代码但留下 bug、没记录进展 → progress notes + git commit 充当显式状态。
- 标记完成但没验证 → 要求 agent 自我验证,配浏览器测试工具让它看到 UI 级别的错误。
- 每次启动都花大量时间研究怎么把项目跑起来 → init script 一次生成、持久保留。
背后的统一思路:harness 建立了一套结构性的回拽力,让模型走偏时有机会被纠正。它把模糊的"完成这个任务"翻译成了可以接续、可以检查、可以修复的操作条件。
还有一点值得注意:harness 中的每个组件都编码着一个关于"模型哪里不够用"的假设。模型能力变了,假设就可能失效。Anthropic 做前端 DAW 任务时,曾引入 sprint 式的任务分解结构,后来新模型规划能力明显提升,就直接把 sprint 拿掉了。反过来说,正因为 harness 设计是显式的,你才能精确判断哪段结构已经多余,而不是让所有脚手架都在维护中慢慢变成历史遗留。
生产环境的 harness 长什么样
Agent 要长期跑、团队不敢放任它单飞时,harness 就不只是一组文件约定了,而是一套可替换、可隔离的基础设施。
Anthropic Managed Agents 的设计切了三层:Session / Harness / Sandbox。Session 是 append-only 事件日志,记录完整运行轨迹;Harness 是调用模型、路由工具调用的循环;Sandbox 是执行代码、编辑文件的隔离环境。三条线各自可以失败、重启甚至替换,互不连带。
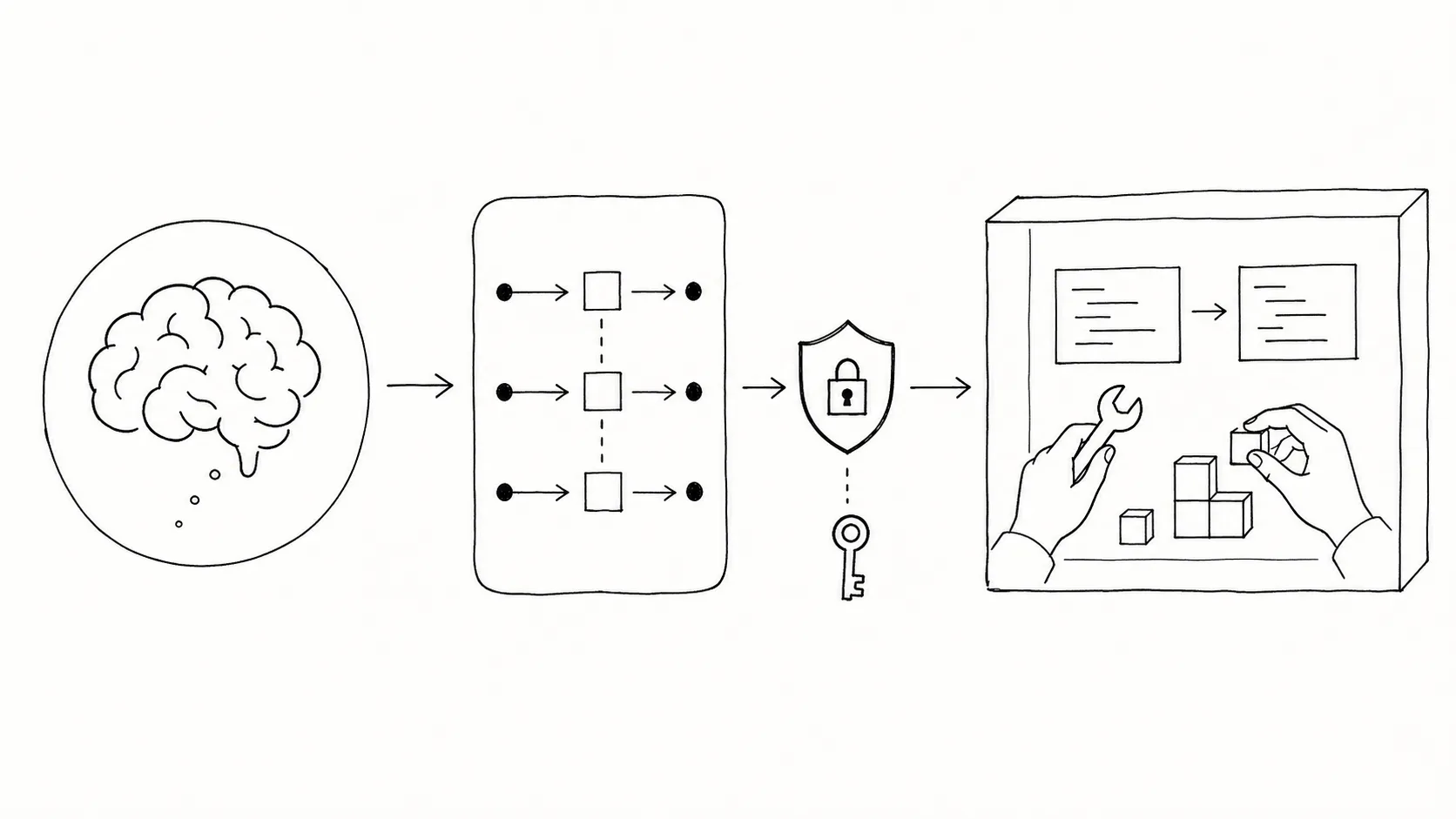
把大脑从双手里分出来的好处横跨两面:可靠性上,容器预置和 agent 推理走独立路径,沙箱启动慢不会卡住模型思考;安全上,credentials 通过代理注入,模型发起的代码执行拿不到密钥本身。
快速自检
对照你正在搭或正在评估的 agent 系统,过一遍这些问题。不必全部复杂实现,但至少想清楚答案:
- 有没有明确的 agent loop,还是一次性 prompt 调用加简单串联?
- 工具定义是否职责清晰、没有重叠,描述和响应是否足够让模型做对决策?
- 进出上下文的信息是否高信号?有没有采用按需加载而不是一股脑灌入?
- 状态是否持久在上下文窗口之外?
- 验证结果时是检查环境中的实际产出,还是只信 agent 自己说的?
- 权限、hooks、预算、停止条件是否明确编码?
- 能否同时采集过程(transcript)和产出(outcome)?
- Credentials 是否与执行环境切实隔离?
- 当前的 harness 是否只为任务所需,保持了简单?
最后一点
把可靠性全押在"下次模型升级就好了"上,等的是外部改进。Harness 提供的是另一条路:你可以主动设计反馈循环、工具契约、状态交接和验证机制。模型换代不会让这些设计失去意义,但会让它们需要重新审视——好的模型让你能做减法,但前提是 harness 把假设显式化了,你才有条理地减,而不是被一堆隐性依赖困住。
工程师的时间值得花在这些可审视、可调试、可修改的结构上。Harness 是从"期待模型表现更好"走向"主动设计工程条件"的分界线。
参考资料
- Mitchell Hashimoto, My AI Adoption Journey: https://mitchellh.com/writing/my-ai-adoption-journey
- Anthropic, Building effective agents: https://www.anthropic.com/engineering/building-effective-agents
- Anthropic, Demystifying evals for AI agents: https://www.anthropic.com/engineering/demystifying-evals-for-ai-agents
- Anthropic, Effective harnesses for long-running agents: https://www.anthropic.com/engineering/effective-harnesses-for-long-running-agents
- Anthropic, Harness design for long-running application development: https://www.anthropic.com/engineering/harness-design-long-running-apps
- Anthropic, Scaling Managed Agents: Decoupling the brain from the hands: https://www.anthropic.com/engineering/managed-agents
- Claude Agent SDK overview: https://platform.claude.com/docs/en/agent-sdk/overview
- Claude Agent SDK, How the agent loop works: https://code.claude.com/docs/en/agent-sdk/agent-loop
- Claude Managed Agents overview: https://platform.claude.com/docs/en/managed-agents/overview
- Anthropic, Effective context engineering for AI agents: https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents
- Anthropic, Writing effective tools for agents — with agents: https://www.anthropic.com/engineering/writing-tools-for-agents
- LangChain, The Anatomy of an Agent Harness: https://blog.langchain.com/the-anatomy-of-an-agent-harness/